



I) Introduction
In a context of a project held by the Clermont Auvergne University and the engineering school SIGMA, we are studying the possibility to create a 3D impression system for concrete. The goal of this system is to be able to put the concrete from a concrete print head at the end of the cable of a hoist. All of this can be done by the help of a vision camera where the sensor will be positioned on the print head to follow people activities on the ground. Thanks to that, we can extract 4 main tasks which are :
-Calibration of the camera, Detection of a sight, Location of the camera compared to the ground and Detection of people.
My team and me decided to work on the dectection of a sight. We have to find a way for the camera to detect in the image/video the sight and to follow it. To do that, we have to detect interest points in a sight reference image (many exemples are available in the library OpenCv) and to find these same interest points in the current image.
II) How does it work ?
As we said before, our goal is, given a query image of our sight and the image/video taken by the camera, to find our sight and follow its position.
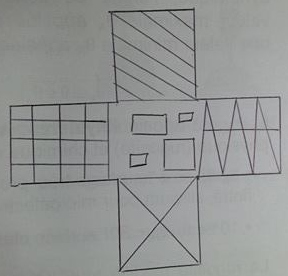
In illustrations 1 and 2, we can see our sight and the image where we want to find our sight (here is a very basical exemple).
1) Research of interest points of our reference sight
The first step of the algorithm is to detect interest points (or interest points) of our reference sight.
A interest point in a picture is a point which has a clear position and which is stable under perturbations such as rotation, translation, scaling, illumination, etc ….The goal is to detect these points, at first in our reference sight then at every frame in the video taken.Multiple algorithms exist to find such points but one of the most famous one is the Harris dectector which is a corner detection algorithm which detect corner.
2) Matching of these points
Now we know how to detect interest points, we need to match the interest points of our reference sight with the interest points of the video To do that, we need a feature descriptor which will be used to compare and match the different interest points.
These 2 previous steps are the « center » of every image detector algorithms.
Now we will study the program himself used for our projet (which was available in OpenCv).
III) Algorithm utilisation examples
For the moment, the algorithm we use is not the final algorithm because in the algorithm we will talk about now, we have to select manually the initial position of the sight and then the sight will be followed in the video.
First, when we execute the algorithm, we have to select (with a green rectangle), the area of the object we want to follow. In my example, we are trying to follow the card, so we selected it and all interest points will be found in this area.

After beeing selected, if we release the clic, we can see that a blue « house » will surround the area selected.
Then even after the video continue, we can see that the « house » keep following the object selected.


While no other area (a new object to follow) is not selected (with green rectangle), the algorithm will keep tracking it.
In the next part we will explain the different sequences of this programm.
IV) Implementation with OpenCv
This process should be fulfiled by using the OpenCV Library in Python language.
We use the preprogrammed sequence plane_ar.py which propose to select a rectangular part of a moving image and tries
to follow it in its movements. Moreover, it builds a 3D-looking "house" above the selected shape which follows it along its movements.
This program is composed of an initialization sequence _init_ that creates the main window and a trackbar that allows the user to adapt the focal of the image. It also allows to create plane zone selectors thanks to common.RectSelector(). This function needs the on_rect() defined function, that adds the selected target to a tracking list using tracker.add_target().
| class App: | |
| def __init__(self, src): | |
| self.cap = video.create_capture(src, presets['book']) | |
| self.frame = None | |
| self.paused = False | |
| self.tracker = PlaneTracker() | |
| cv2.namedWindow('plane') | |
| cv2.createTrackbar('focal', 'plane', 25, 50, common.nothing) | |
| self.rect_sel = common.RectSelector('plane', self.on_rect) | |
| def on_rect(self, rect): | |
| self.tracker.add_target(self.frame, rect) |
We now define a function run(), that will, as its name shows, allow to run the App itself.
Firstly, everything is set to make the gif or the video play ans to pause it while selecting a rectangular zone. Then, using the functions polylines and circle of OpenCV, we set the drawing of the house-shaped cube above the selected zone, and we circle the interest points used for detection.
After everything is drawn and shown thanks to the draw() and imshow() functions of OpenCV, we set two interactions with the window: press «Space» to pause the video/gif and «c» to clear all the trackers.
|
def run(self): |
|
| while True: | |
| playing = not self.paused and not self.rect_sel.dragging | |
| if playing or self.frame is None: | |
| ret, frame = self.cap.read() | |
| if not ret: | |
| break | |
| self.frame = frame.copy() | |
| vis = self.frame.copy() | |
| if playing: | |
| tracked = self.tracker.track(self.frame) | |
| for tr in tracked: | |
| cv2.polylines(vis, [np.int32(tr.quad)], True, (255, 255, 255), 2) | |
| for (x, y) in np.int32(tr.p1): | |
| cv2.circle(vis, (x, y), 2, (255, 255, 255)) | |
| self.draw_overlay(vis, tr) | |
| self.rect_sel.draw(vis) | |
| cv2.imshow('plane', vis) | |
| ch = cv2.waitKey(1) | |
| if ch == ord(' '): | |
| self.paused = not self.paused | |
| if ch == ord('c'): | |
| self.tracker.clear() | |
| if ch == 27: | |
|
break |
|
Finally, we set a function draw_overlay() in which everything is defined to put the 3D reconstitution of the house-shaped cube in place on the tracked points. Indeed, it sets a transformation matrix K and creates a 3D projection thanks to the OpenCV function projectPoints().
| def draw_overlay(self, vis, tracked): | |
| x0, y0, x1, y1 = tracked.target.rect | |
| quad_3d = np.float32([[x0, y0, 0], [x1, y0, 0], [x1, y1, 0], [x0, y1, 0]]) | |
| fx = 0.5 + cv2.getTrackbarPos('focal', 'plane') / 50.0 | |
| h, w = vis.shape[:2] | |
| K = np.float64([[fx*w, 0, 0.5*(w-1)], | |
| [0, fx*w, 0.5*(h-1)], | |
| [0.0,0.0, 1.0]]) | |
| dist_coef = np.zeros(4) | |
| _ret, rvec, tvec = cv2.solvePnP(quad_3d, tracked.quad, K, dist_coef) | |
| verts = ar_verts * [(x1-x0), (y1-y0), -(x1-x0)*0.3] + (x0, y0, 0) | |
| verts = cv2.projectPoints(verts, rvec, tvec, K, dist_coef)[0].reshape(-1, 2) | |
| for i, j in ar_edges: | |
| (x0, y0), (x1, y1) = verts[i], verts[j] | |
|
cv2.line(vis, (int(x0), int(y0)), (int(x1), int(y1)), (255, 255, 0), 2)
|
Then the main function is implemented. It simply runs the main App and set a default image if none is submitted by the user while calling the main program.
| if __name__ == '__main__': | |
| print(__doc__) | |
| import sys | |
| try: | |
| video_src = sys.argv[1] | |
| except: | |
| video_src = 0 | |
| App(video_src).run() |
V) Test using our own materials
Encountering problems with the OpenCV library, we decided to cut the videos into multiple images thanks to the filezigzag.com website. We now input the treated video as a sequence of following images to avoid error using the command cv2.VideoCapture('im/%08d.ppm'). Thanks to this advanced process we managed to read our own videos. Then we could launch the plane_ar.py program with custumized videos to test the recognition of our sight. (unfortunately, we can't take screenshot of our video because there are some problems with the virtual machine)
VI) Conclusion
The aim will now be to find a way to give the program our card as a reference instead of selecting a rectangle zone manually. Therefore, it will be able to spot the whished shape in the image automatically and to follow it through its movements. To do so, we are thinking about removing the function RectSelector() and to find a way to pass our reference image as an argument.