



Project n°4: Person detection
The goal of the project is to detect moving persons on a video using deep learning methods. We teach the neural network to detect persons on images by learning from an annotated database. More specifically we will use the SSD method thanks to the tensorflow module on python.
I) Convolutionnal networks.
This method uses convolutional neural networks, that is to say neural networks that have convolutionnal layers:
A convolutional layer is composed of packs of neurones, each pack only processes a certain window in the initial image. A retropropagation algorithm is used to modify the activation filters that each neurone applies to the window it is assigned to.
A pooling (agregation) layer is often applied to reduce the dimension of the output after a convolutionnal layer.The outputs are then connected to a fully connected layer (a layer in which each neurone is connected to every output of the previous layer) to allow an overall processing of the information.
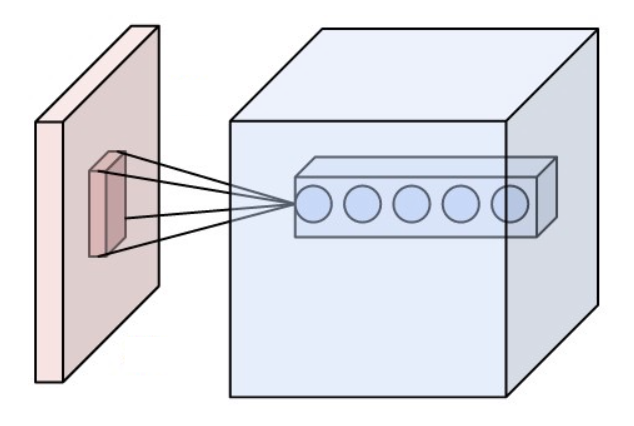
Scheme of a convolutional layer (in blue) applied on an image (in pink)
This type of network is particularly relevant as far as image recognition is concerned, as it processes information at the local scale (which is ideal for border recognition for example) allowing a much faster and adapted processing.
II) VGG network
The VGG network is a a multi-layer convolutional network that aims to predicts the probability of presence of object classes in the image. Convolutional layers are applied to the inputted image, followed by a pooling layer, then convolutional layers are applied again and so on. After several iterations, each
reducing the dimension of the output, fully connected layers are applied and finally a classification layer gives the output probability for each class of object.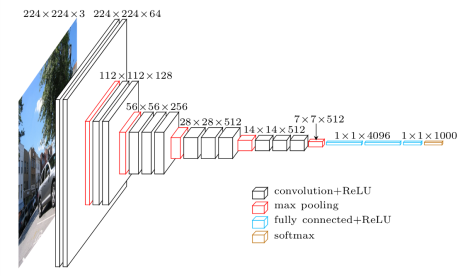
Scheme of a VGG network
This model of network is one of the most efficient for image recognition, it managed to attain more than 92 % of successful recognition on the image net database.
III) SSD network
The SSD network, standing for Single Shot multibox Detector, it is a method for detecting objects in an image using a single deep neural network. It's part of the family of networks which predict the bounding boxes of objects in a given image.It is a simple, end to end single network, removing many steps involved in other networks which tries to achieve the same task.
The SSD network uses the VGG architecture as a base. But instead of trying to classify the image after in went through the VGG, we remove the fully connected layer at the end of VGG. Then we apply several convolutional layers, the output of the VGG as well as the outputs of every following layers (of decreasing dimensions) are all connected to a fully connected layer that computes all this information ...
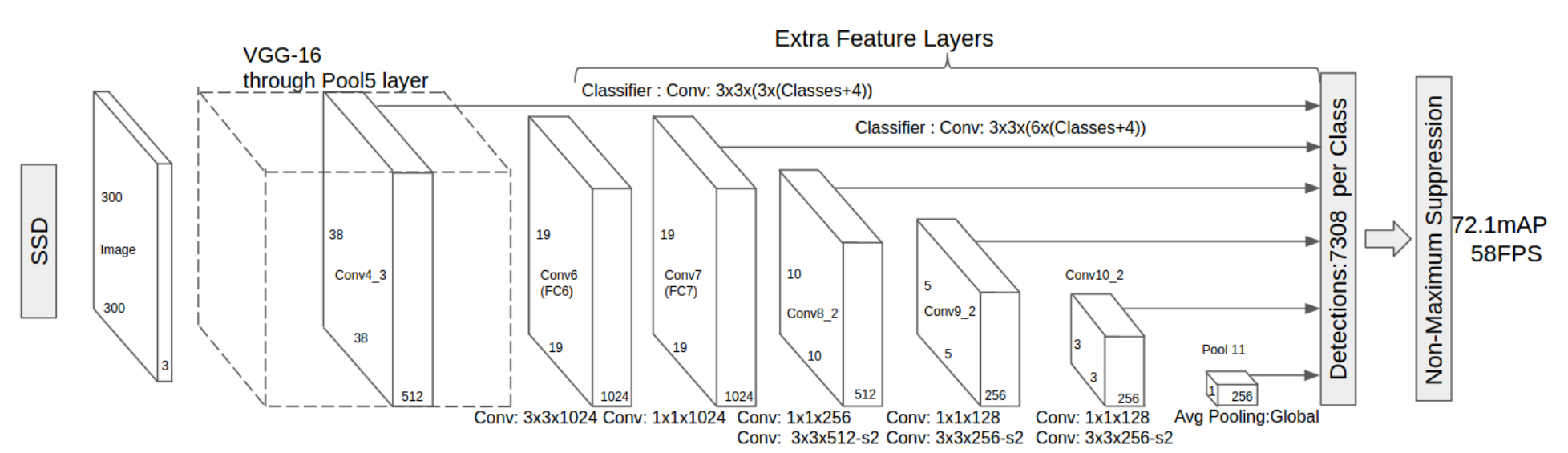
A SSD scheme
iV) Code explanation
The lines below explain some parts of the codes of SSD Framework :
The demo folder contains a set of images for testing the SSD algorithm in the main file.
The Notebook folder contains a minimal example of the SSD TensorFlow pipline. Basically, the detection is made of two main steps:
1) Running the SSD network on the image
2) Post-processing the output(putting a rectangle on the detected object with a number which design the class where the object belongs).
Example: